本文聚焦于GTC2025大会上理想汽车和英伟达在自动驾驶领域的最新进展。理想汽车公开了全栈自研的MindVLA模型,展示了其多方面的技术优势;英伟达则从四个关键领域介绍了端到端自动驾驶技术的应用,双方共同推动自动驾驶技术迈向新高度。


在“老黄”演讲之前,理想汽车率先打出了一张王牌。车东西于3月18日(圣何塞时间3月17日晚)报道,就在不久前,理想汽车与英伟达自动驾驶部门共同带来了一系列采用英伟达自动驾驶基座的量产产品以及前沿研究进展。
在当日的GTC2025大会上,理想汽车智驾负责人贾鹏首次对外公布了理想汽车在封闭开发VLA技术后的最新成果。此前,曾有媒体报道称,理想汽车为攻克VLA技术开启了封闭开发模式,目标是在2025年下半年实现VLA技术的量产上车。
当下,VLA(视觉 - 语言 - 行动)模型已然成为今年智能驾驶领域的重要技术竞争焦点。目前,理想汽车、吉利汽车和元戎启行是该技术的主要推动者,这三家公司都期望在VLA的实际应用方面占据领先地位,这也很好地解释了理想汽车决定封闭开发的原因。
然而,VLA技术的落地仍面临诸多难题。除了模型本身的研发需要耗费大量时间外,硬件性能的限制也是关键因素之一。目前,Thor - U是较为平衡的解决方案。
此外,在上午的会议中,英伟达方面详细介绍了如何通过世界模型、神经重建引擎(NRE)、数据中心训练加速以及端侧优化部署,来提升自动驾驶系统的整体性能。同时,英伟达还着重展示了车企使用Thor芯片针对自动驾驶的端侧优化成果,秀了一把实力。
不难发现,这两场演讲的核心共同点在于,都强调了通过大规模数据训练、模型优化以及计算加速,推动自动驾驶技术朝着更智能、更高效的方向发展,同时也预示着新一代自动驾驶系统形态的演变。
一、理想拿出VLA技术 交卷GTC2025
理想汽车在2025年NVIDIA GTC大会上正式发布了其全栈自研的MindVLA(视觉 - 语言 - 行动模型),该模型融合了空间智能、语言智能和行为智能。
MindVLA不仅能够理解复杂的3D空间环境,还能进行逻辑推理,并据此制定合理的驾驶决策,让车辆真正具备感知、思考和自主行动的能力。它的核心技术优势主要体现在以下六个方面:
首先,MindVLA采用3D高斯(3D Gaussian)作为核心中间表征。这种技术不仅具有丰富的语义表达能力,还能提供多粒度、多尺度的3D几何表达,使自动驾驶系统能够高效地感知和理解周围环境。同时,系统通过自监督学习充分利用海量数据,进一步提升了各类下游任务的性能。
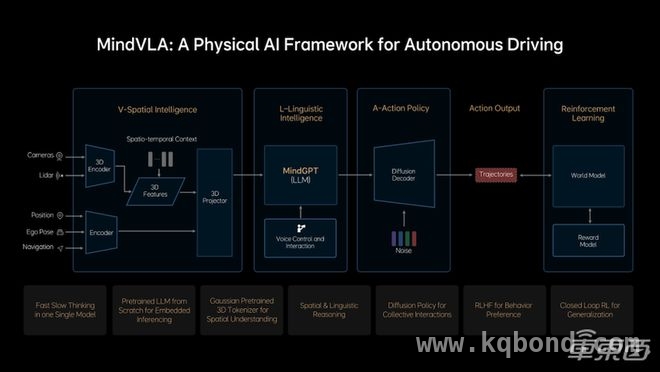
▲MindVLA概述
其次,MindVLA在模型架构上采用MoE架构,并引入稀疏注意力(Sparse Attention),实现了模型的稀疏化。这种设计在保证模型规模增长的同时,能够维持较高的端侧推理效率,使自动驾驶在资源受限的车端环境中依然能够高效推理。此外,理想团队从零开始设计并训练了专门适用于MindVLA的LLM基座模型,在训练过程中引入了大量3D数据,使模型具备出色的3D空间理解和推理能力,并加入未来帧预测生成和稠密深度预测等任务,进一步增强空间智能。
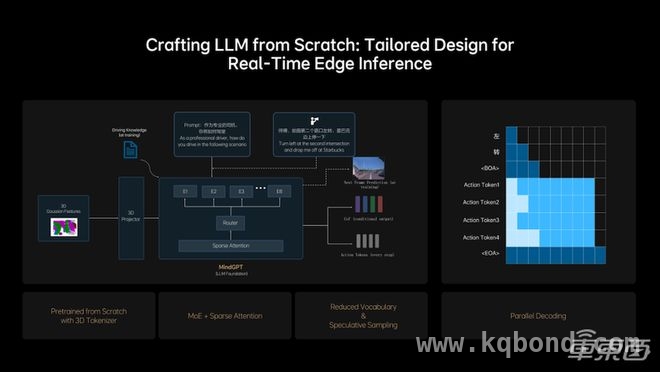
▲MindVLA在模型架构上采用MoE架构
第三,MindVLA大幅提升了自动驾驶系统的逻辑推理能力。理想在训练过程中让LLM基座模型学习人类的思考方式,并引入“快思考”和“慢思考”的有机结合,使其能够根据不同驾驶情境自主切换决策模式。这一能力使得MindVLA不仅能在常规驾驶场景中做出快速反应,也能在复杂环境下进行深度推理,从而做出更安全、更合理的驾驶决策。
同时,为了充分利用NVIDIA Drive AGX的算力,MindVLA采用小词表结合投机推理,并创新性地应用并行解码技术,进一步提升了推理速度,使其在保持高精度的同时,仍能满足实时性要求。
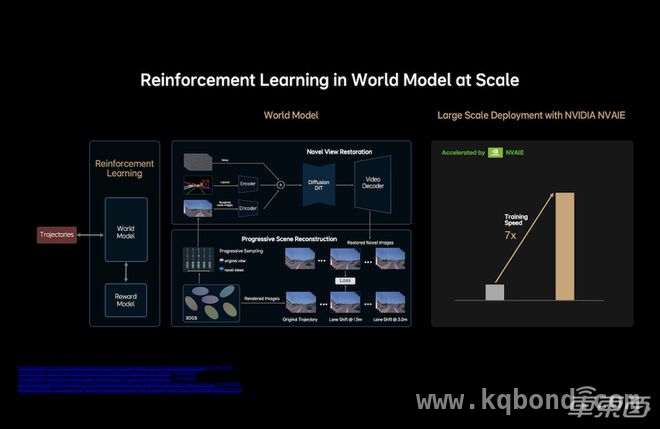
▲通过英伟达实现效率7倍提升
第四,MindVLA利用扩散模型(Diffusion Model)优化驾驶轨迹,并结合自车行为生成和他车轨迹预测的联合建模,增强了自动驾驶系统在复杂交通环境中的博弈能力。通过这种方式,MindVLA不仅能够基于当前交通流态势预测合理的驾驶策略,还能够根据外部条件(如风格指令)动态调整生成结果。
例如,在不同城市环境中,系统可以适应不同的驾驶风格,从而提供更加符合当地交通规则和驾驶习惯的体验。值得一提的是,为了解决扩散模型计算效率较低的问题,MindVLA采用了基于常微分方程(Ordinary Differential Equation, ODE)的采样器,使得系统能够在仅2 - 3步内生成高质量的驾驶轨迹,大幅提升了推理效率。此外,为了增强自动驾驶在复杂和极端场景下的安全性,理想团队构建了基于人类偏好的数据集,并创新性地引入RLHF(基于人类反馈的强化学习)进行模型微调,使MindVLA能够更好地对齐人类驾驶行为,显著提升了安全底线。
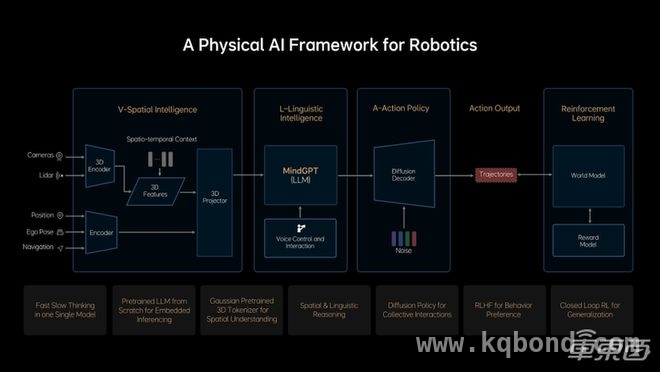
▲MindVLA架构
第五,MindVLA基于自研的“重建 生成”云端统一世界模型,具备高度精准的仿真能力。该模型结合了三维场景重建技术和新视角补全能力,使系统能够构建接近真实世界的仿真环境,并在此基础上进行大规模闭环强化学习(RL),即在仿真环境中通过不断试错和优化,逐步提升自动驾驶的决策能力。
过去一年,理想自动驾驶团队完成了大量工程优化,极大地提升了场景重建与生成的质量和效率,其中最显著的成果之一是将3D高斯(3D GS)的训练速度提升至7倍以上。这一突破不仅让MindVLA在虚拟环境中实现了高效学习,也使得自动驾驶系统能够更快适应现实世界中的复杂交通情况。
第六,MindVLA在训练和优化过程中采用了创新性的预训练和后训练方法,具备卓越的泛化能力和涌现特性。这意味着它不仅能够在自动驾驶场景中表现出色,还能够在室内环境等其他领域展现一定的适应性和拓展性。通过这种方式,MindVLA不仅使自动驾驶系统更智能,也为未来更多物理智能体的发展提供了可行的技术方案。

▲理想汽车目标:每个人的专职司机
基于这六大技术创新,MindVLA赋能的车辆不再仅仅是一个交通工具,而是一个能够与用户交互、理解用户意图并自主执行任务的“专职司机”。
具体而言,MindVLA让汽车具备“听得懂、看得见、找得到”三大核心能力。“听得懂”指的是用户可以通过语音指令直接控制车辆的路线和行为。
从整体来看,MindVLA的推出不仅重新定义了自动驾驶技术,也进一步推动了人工智能与物理世界的深度结合。
对于用户而言,搭载MindVLA的汽车不再只是驾驶工具,而是一个具备高级认知能力的智能体。
对于汽车行业而言,MindVLA的问世有望像iPhone 4之于智能手机行业一样,彻底革新自动驾驶的形态。
对于人工智能领域而言,MindVLA展示了物理人工智能的发展潜力,并为未来物理世界与数字世界的融合提供了全新的技术路径。
与此同时,理想汽车也在持续推动技术创新,并在人工智能领域的顶级学术会议和期刊上发表了大量研究成果。
二、从仿真到部署 英伟达四大方向详解端到端智驾
在自动驾驶专题论坛上,英伟达方面在四个关键领域介绍了其在端到端自动驾驶技术中的应用,分别是世界模型、神经重建引擎(NRE)、模型训练加速以及自动驾驶端侧优化部署。
世界模型(World Model)最早于2018年在NIPS大会上被提出,其核心思想是模拟人类认知过程,包括感知、推理和决策,使人工智能系统能够理解环境、预测未来状态,并做出合理的控制决策。在自动驾驶领域,世界模型通过整合视觉模型、循环神经网络(RNN)和控制模块,实现对传感器输入(如摄像头和激光雷达)的解析,并生成合理的未来轨迹和行动指令。
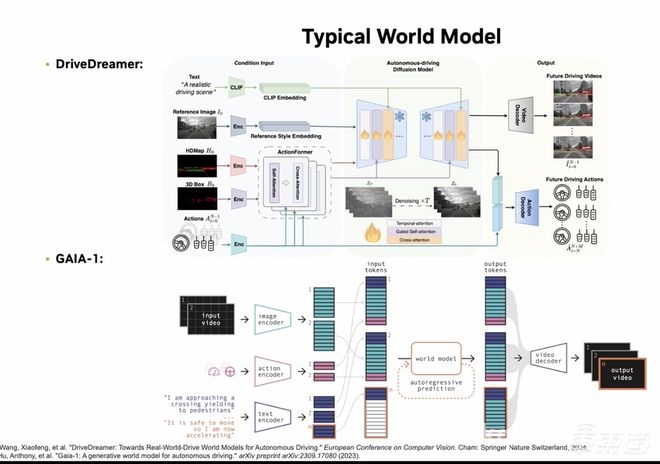
▲Typical World Model概述
近期,英伟达推出的NVIDIA Cosmos作为前沿世界模型之一,专注于自动驾驶场景的生成与预测,利用扩散模型(Diffusion Model)和自回归模型(Autoregressive Model)等架构,提高生成内容的真实性与一致性,以适应自动驾驶系统对未来视频和轨迹预测的需求。
与此同时,神经重建引擎(Neural Reconstruction Engine,NRE)在自动驾驶领域的应用也十分关键。NRE基于神经辐射场(NeRF)和三维高斯(3D Gaussian)技术,通过从真实世界采集的二维图像和激光点云重建高精度的三维场景,并渲染高逼真的传感器数据,为自动驾驶仿真测试提供更加真实的环境。
相比传统游戏引擎式的仿真系统,NRE具备更强的真实性和可泛化性,并支持对各类传感器(如环视摄像头、前视摄像头和激光雷达)的准确建模,以优化自动驾驶感知系统的性能。

▲NRE在多传感器场景下的状态
此外,NRE可生成新视角传感器帧,使自动驾驶系统能够在更复杂的场景下进行仿真测试,并结合生成式AI技术,为自动驾驶行业提供高效的仿真与训练解决方案。这些前沿技术的结合,为自动驾驶系统的优化和安全性提升奠定了重要基础。
在模型训练加速方面,会议重点介绍了视频与图像训练流水线(Pipeline)的优化策略,核心库(Core Lib)算子的高效运算方式,以及如何通过损失计算(Loss Calculation)的加速提升数据中心训练效率。
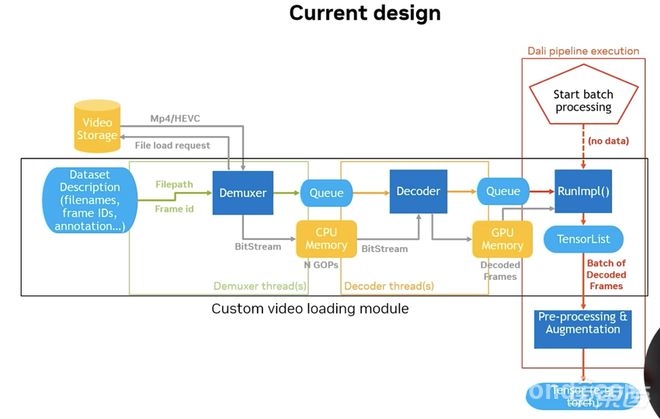
▲高效编码设计怪概述
专家指出,自动驾驶感知模型消耗大量计算资源,而优化数据加载、预处理和算子执行,能够显著提升训练并行度。例如,利用GPU加速JPEG解码并优化Bounding Box计算,实现了5.17倍的训练加速。同时,在视频训练方面,通过按需解码(On - demand Video Decoding)技术,有效减少存储与带宽占用,使训练过程更高效。
在自动驾驶端侧模型优化部署方面,与会嘉宾分享了Thor平台的模型优化策略。Thor基于Blackwell架构,提供高达1000 TOPS的INT8推理算力,并集成第五代Tensor Core,具备32MB L2 Cache。此外,它针对大模型(如VLM,视觉语言模型)进行了深度优化,提供2000 TOPS FP4计算能力,并结合Flash Attention技术提升推理效率。
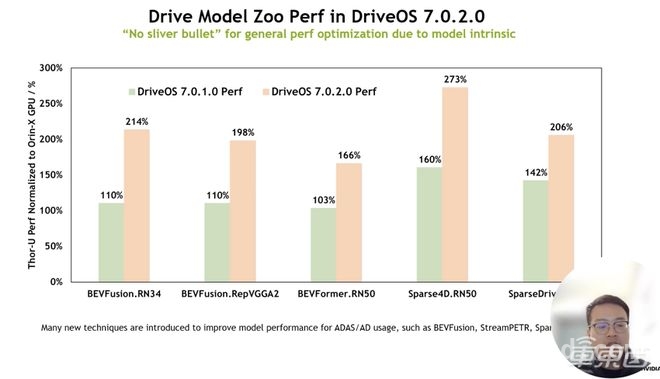
▲在最新版本Drive OS下的模型性能提升
在Thor平台 TensorRT 10的优化下,多个自动驾驶模型的推理效率得到了大幅提升。4D BEV变换网络推理速度提升2倍;端到端自动驾驶VLM(Vision - Language Model)在Drive OS 7.0.2上提升1.5倍计算吞吐量;而高分辨率4D Radar处理任务在TensorRT 10优化后,推理延迟减少30%。
通过Transformer类网络计算。结合先进的推理引擎和GPU调度策略,Thor平台可高效运行端到端(E2E)自动驾驶模型,实现更精确的环境感知、轨迹预测和规划决策。
本文详细介绍了GTC2025大会上理想汽车和英伟达在自动驾驶领域的重要进展。理想汽车推出全栈自研的MindVLA模型,具备六大核心技术优势,重新定义了自动驾驶技术,推动了人工智能与物理世界的深度融合;英伟达则从世界模型、神经重建引擎、模型训练加速和端侧优化部署四个方面,展示了端到端自动驾驶技术的应用,提升了自动驾驶系统的整体性能。双方的成果共同为自动驾驶技术的发展注入了新动力,预示着该领域将迎来新的变革。
原创文章,作者:Lambert,如若转载,请注明出处:https://www.kqbond.com/archives/396.html





